Uurimuse eesmärk oli tuvastada ukraina ja eesti rahvalaulude temaatilist kattuvust, kultuurilisi sarnasusi ja ainuomaseid teemasid arvutuslike meetodite abil, kasutades eelkõige tehisintellektipõhist tõlget ja LDA-teemamodelleerimist.
Kuigi ukraina ja eesti rahvalaulud esindavad erinevaid keele- ja kultuuritraditsioone (läänemeresoome ja idaslaavi), on mõlemat kultuuri ühendanud ajaloolised kontaktiperioodid, mis võivad kajastuda ka rahvapärimuses. Juba varakeskajal ühendasid mõlemat piirkonda põhja–lõunasuunalised kaubateed, eelkõige Läänemere ja Musta mere vaheline varjaagide tee (Pritsak 1981). Need kaubateed soodustasid lisaks kaubavahetusele ka narratiivsete motiivide, rituaalsete struktuuride ja mütoloogiliste kujutelmade levikut. Vaatamata keelelisele kaugusele ilmneb nii ukraina kui ka eesti folklooris märkimisväärseid temaatilisi paralleele, mis teeb need traditsioonid võrdleva analüüsi jaoks eriti sobivaks.
Uurimus keskendus kolmele põhiküsimusele: (1) Milliseid teemasid, motiive ja narratiivseid struktuure saab ukraina ja eesti rahvalauludest teemamodelleerimise abil tuvastada? (2) Kuidas sobituvad arvutuslikult tuvastatud temaatilised struktuurid traditsiooniliste folkloristlike klassifikatsioonidega? (3) Kuidas mõjutab tõlke kasutamine kahe keele temaatilise kattuvuse analüüsi?
- Autorid:
- Olha Petrovych (Eesti Kirjandusmuuseum)
- Mari Väina (Eesti Kirjandusmuuseum)
- Kaarel Veskis (Eesti Kirjandusmuuseum & Tartu Ülikool)
- Liina Saarlo (Eesti Kirjandusmuuseum)
- Töövoog on loodud kõigi autorite poolt (st see on kavandatud, arendatud ja rakendatud ühiselt), mõned meeskonnaliikmed on andnud suurema panuse töövoo praeguse kirjelduse koostamisse, kuid selle loomise autorlus kuulub kõigile meeskonnaliikmetele.
- Litsents: Creative Commons Attribution 4.0 International
- Märksõnad (sisu): regilaulud, rahvaluule
- Märksõnad (Tadirah): Teemade modelleerimine, Tõlkimine, Võrdlemine, Andmete visualiseerimine, Tõlgendamine
- Eriala: arvutuslik folkloristika
- Andmete meediatüüp: tekst
- Väljund: teadusartikkel, andmestik, visualiseering
- Seotud materjalid:
- Viide: Petrovych, Olha, Väina, Mari, Veskis, Kaarel, Saarlo, Liina (2026). Ukraina ja eesti rahvalaulude võrdlev teemaanalüüs tehisintellektipõhise tõlke ja arvutuslike meetodite abil. https://www.etkad.ee/humal/toovood/ukrainian-and-estonian-folk-songs/
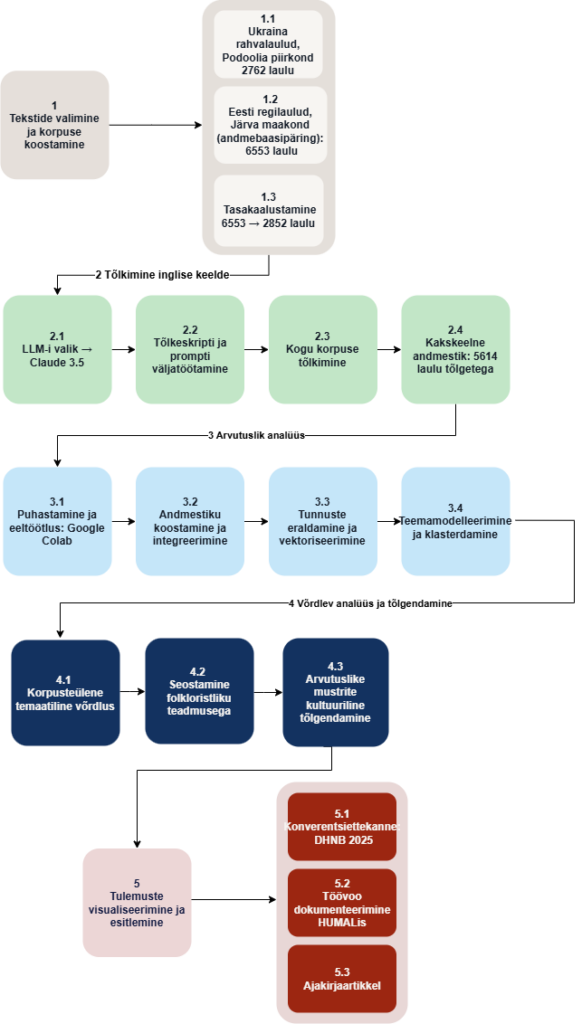
TÖÖVOO SAMMUD
Kasutatud kirjandus
Dei, Oleksii (red.). 1965. Pisni Yavdokhy Zuikhy: zapysav Hnat Tantsiura [Songs of Yavdokha Zuikha: recorded by Hnat Tantsiura]. Kyiv : Naukova dumka. 810 s.
Dmytrenko, Mykola & Liudmyla Yefremova (red.). 2014. Narodni pisni Khmelnychchyny (z kolektsii zbyrachiv folkloru) [Folk songs of Khmelnytskyi region (from the collections of folklore collectors)]. Kyiv: Naukova dumka. 720 s.
Myshanych, Stepan (red.). 1976. Pisni Podillia: zapysy Nasti Prysiazhniuk v seli Pohrebyshche. 1920-1970 rr. [Songs of Podillia: recordings of Nastia Prysiazhniuk in the village of Pohrebyshche. 1920-1970.] Kyiv: Naukova dumka. 520 p.
Pritsak, Omeljan (1981). The Origin of Rus: Old Scandinavian Sources Other than the Sagas. Cambridge, Massachusetts: Harvard University Press
Sarv, Mari & Janika Oras,. 2020. From tradition to data: The case of Estonian runosong. In: Arv. Nordic Yearbook of Folklore, 76, 105−117.