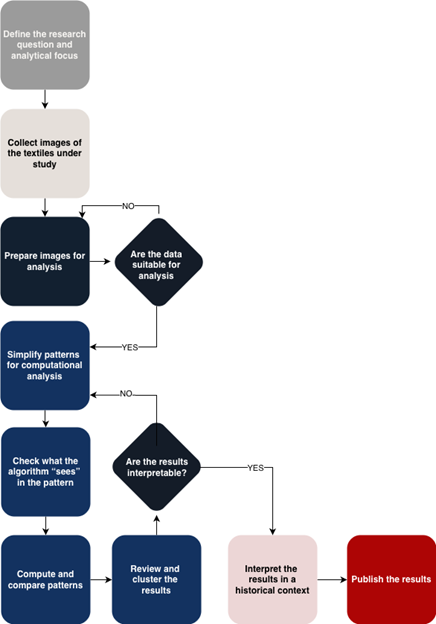
This workflow describes how image-based patterns are compared using machine learning methods. The aim is to investigate the pattern logic that characterised Estonian striped skirts of the 18th–19th centuries and to examine how these patterns relate to striped, glazed-surface woollen callimanco fabrics produced at the Norwich factory in England. The workflow combines digital humanities approaches with machine learning. For analysing large image datasets, we use machine learning models designed for visual pattern recognition, specifically convolutional neural networks (CNNs). CNNs are used primarily for extracting visual features and assessing pattern similarity, rather than for training a new model from scratch. Using CNNs, we compare stripe rhythms, colour usage, and structural features, and identify possible similarities between the two textile types. The central research question is whether Estonian folk costume skirts were inspired by specific imported fabrics, and which visual features best explain this relationship.
The workflow describes the process from collecting and standardising images from museum collections to interpreting the results of pattern analysis. At present, the research is in the phase of interpreting analytical results.
- Authors:
- Tiina Kull (Estonian National Museum)
- Kata Maria Metsar (Estonian National Museum)
- Licence: CC BY 4.0
- Date/version: 15.12.2025
- Keywords (content): national costumes, patterns, comparative analysis, cultural heritage
- Keywords (Tadirah): Relational analysis, Pattern recognition, Machine learning, Comparing
- Subject field: ethnology
- Data meida type Image
- Related materials:
- Kull, Tiina (2024). Traces of callimanco in Estonia: purchased worsted striped fabrics from the late 18th to early 19th centuries. Studia Vernacula, 16, 66−93.