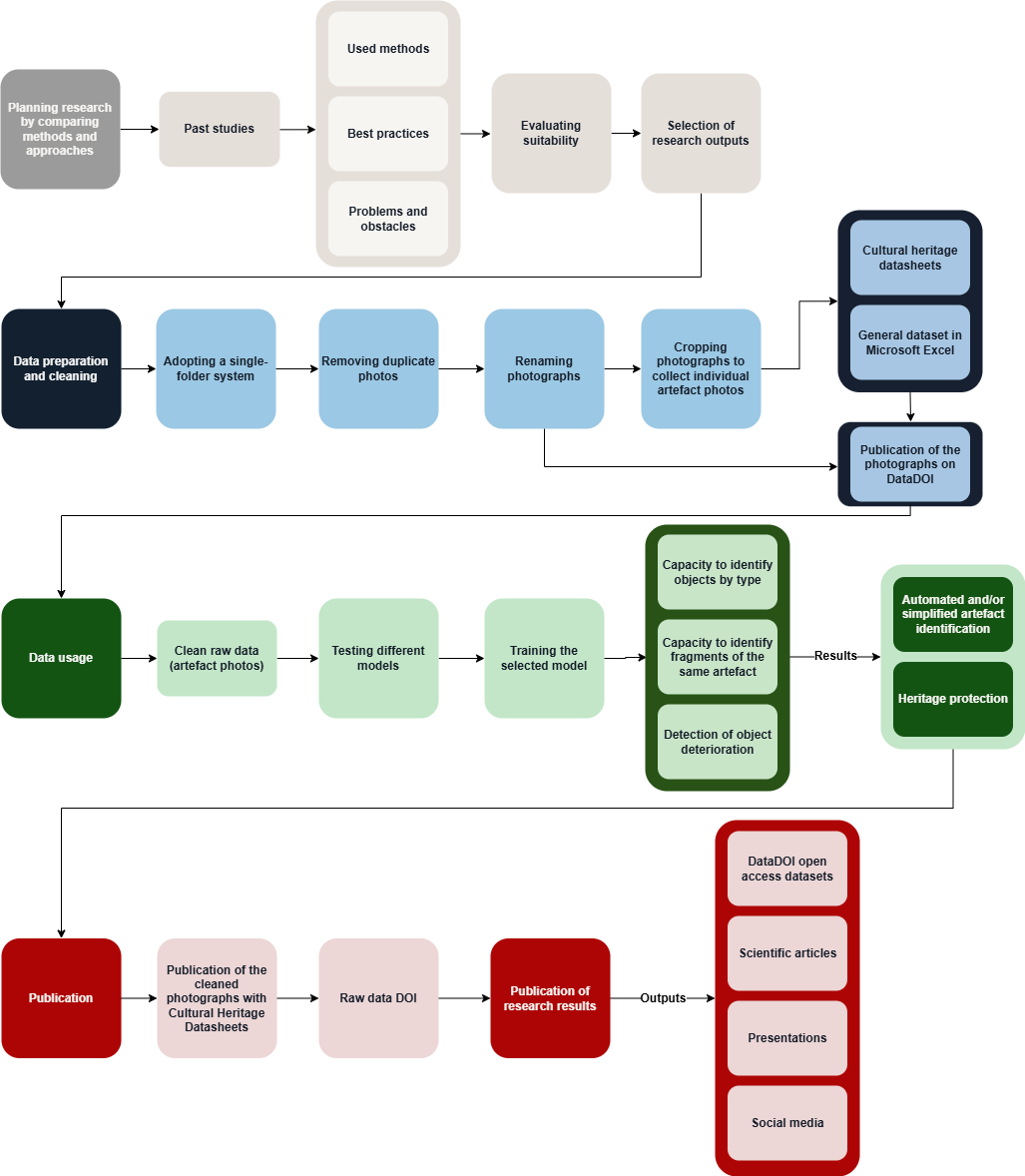
This project investigates how working photographs collected by material culture researchers can be used to automatically identify objects and assess their condition, and how such a large collection can be published under FAIR principles in a user-friendly way. Researchers of material culture may take thousands of photos of objects within the scope of each research topic, but in most cases, the use of photos is limited to typological identification, visual comparison of finds, and, in the case of better-formatted photos, illustration of works. At the end of the project, however, most of the photos taken are simply stored on the researchers' hard drives.
The project uses photos of archaeological glass finds taken between 2012 and 2024 in Estonia, which were photographed during the data collection phase of Monika Reppo’s master's and doctoral theses to catalogue the finds. The photos are of varying quality and were taken with several different devices. The aim of the project is to clean and publish the largely unpublished raw data (approx. 15,000 photos) of the objects preserved in Estonian memory institutions, and to determine whether it is possible to use artificial intelligence to collect additional data from the photos, for example, to automatically identify object types or detect the deterioration of an object.
- Authors:
- Monika Reppo (Tallinn University archaeological research collection)
- Mahendra Mahey (Tallinn University Strategy Office)
- Licence: CC-BY-NC-4.0
- Date/version: 15.01.2026
- Subject field: archaeology, material culture studies
- Data media type: Image
- Keywords (content): historical archaeology, archaeoinformatics, archaeological finds, machine vision
- Keywords (Tadirah): Data cleansing, Publishing, Machine learning, Permanent identifier
- Output: Scholarly article, Dataset
- Related materials:
- Reppo, Monika (2023). Dataset 1. Archaeological glass finds from Estonia.