The aim of the research was to identify thematic overlap, cultural similarities, and unique topics in Ukrainian and Estonian folk songs using computational methods, particularly LLM translation and LDA topic modelling.
Although the two nations belong to different linguistic and cultural traditions (Finnic and East Slavic), they shared periods of historical contact that may be reflected in their folklore. From the early Middle Ages, both regions were connected through northern–southern trade networks, most notably the “Varangian to Greek” route linking the Baltic and Black Sea regions (Pritsak 1981). These channels of exchange facilitated not only economic exchange but also the transmission of narrative motifs, ritual structures, and mythological ideas. Both Ukrainian and Estonian folklore exhibit notable thematic parallels despite their linguistic distance, making them particularly well-suited for comparative analysis.
The research addresses three primary questions: (1) What underlying themes, motifs, and narrative structures can be identified within Ukrainian and Estonian folk songs using topic modelling? (2) How do the thematic structures derived from computational analysis align with traditional folkloristic classifications? (3) How does the use of translation impact the analysis of thematic overlap between these two languages?
- Authors:
- Olha Petrovych (Estonian Literary Museum)
- Mari Väina (Estonian Literary Museum)
- Kaarel Veskis (Estonian Literary Museum & University of Tartu)
- Liina Saarlo (Eesti Kirjandusmuuseum)
- The workflow is authored by all the participants (i.e it was designed, developed and implemented collaboratively), some members of the team contributed more to the current description of the workflow, but the authorship of its invention belongs to everyone in the team.
- Licence: Creative Commons Attribution 4.0 International
- Keywords (content): runo songs, folklore
- Keywords (Tadirah): Topic Modeling, Translating, Comparing, Data visualization, Interpreting
- Subject field: computational folkloristics
- Data media type: text
- Output: scholarly article, dataset, data visualization
- Related materials:
- Reference: Petrovych, Olha, Väina, Mari, Veskis, Kaarel, Saarlo, Liina (2026). Comparative Topic Analysis of Ukrainian and Estonian Folk Songs Using AI Translation and Computational Methods. https://www.etkad.ee/en/humal/toovood/ukrainian-and-estonian-folk-songs/
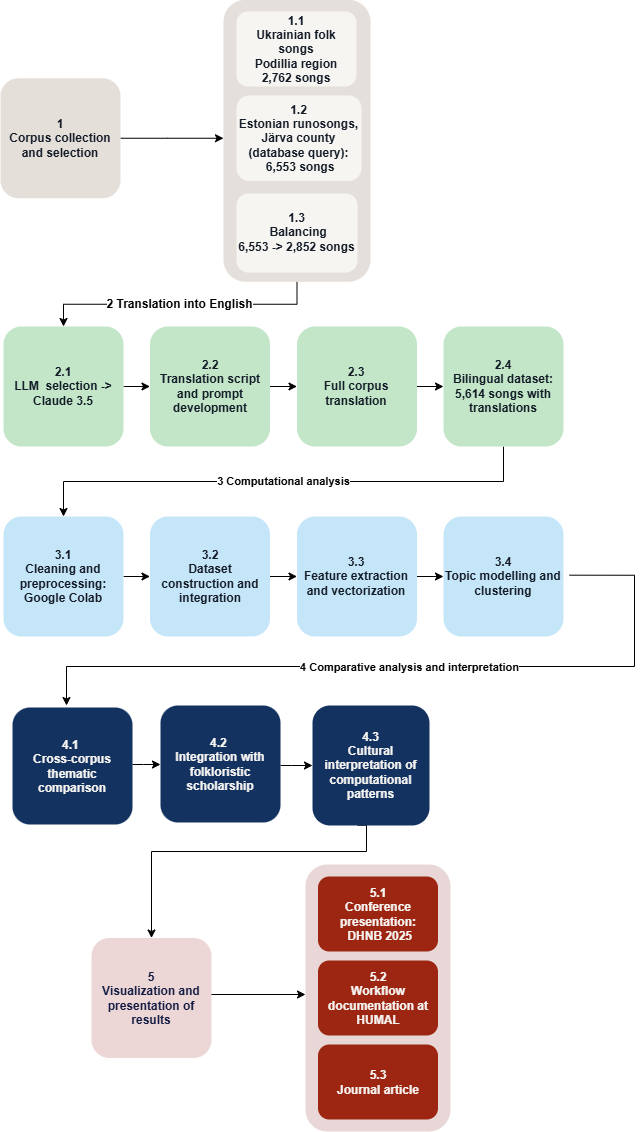
Workflow steps
Works cited
Dei, Oleksii (red.). 1965. Pisni Yavdokhy Zuikhy: zapysav Hnat Tantsiura [Songs of Yavdokha Zuikha: recorded by Hnat Tantsiura]. Kyiv : Naukova dumka. 810 s.
Dmytrenko, Mykola & Liudmyla Yefremova (red.). 2014. Narodni pisni Khmelnychchyny (z kolektsii zbyrachiv folkloru) [Folk songs of Khmelnytskyi region (from the collections of folklore collectors)]. Kyiv: Naukova dumka. 720 s.
Myshanych, Stepan (red.). 1976. Pisni Podillia: zapysy Nasti Prysiazhniuk v seli Pohrebyshche. 1920-1970 rr. [Songs of Podillia: recordings of Nastia Prysiazhniuk in the village of Pohrebyshche. 1920-1970.] Kyiv: Naukova dumka. 520 p.
Pritsak, Omeljan (1981). The Origin of Rus: Old Scandinavian Sources Other than the Sagas. Cambridge, Massachusetts: Harvard University Press
Sarv, Mari & Janika Oras,. 2020. From tradition to data: The case of Estonian runosong. In: Arv. Nordic Yearbook of Folklore, 76, 105−117.