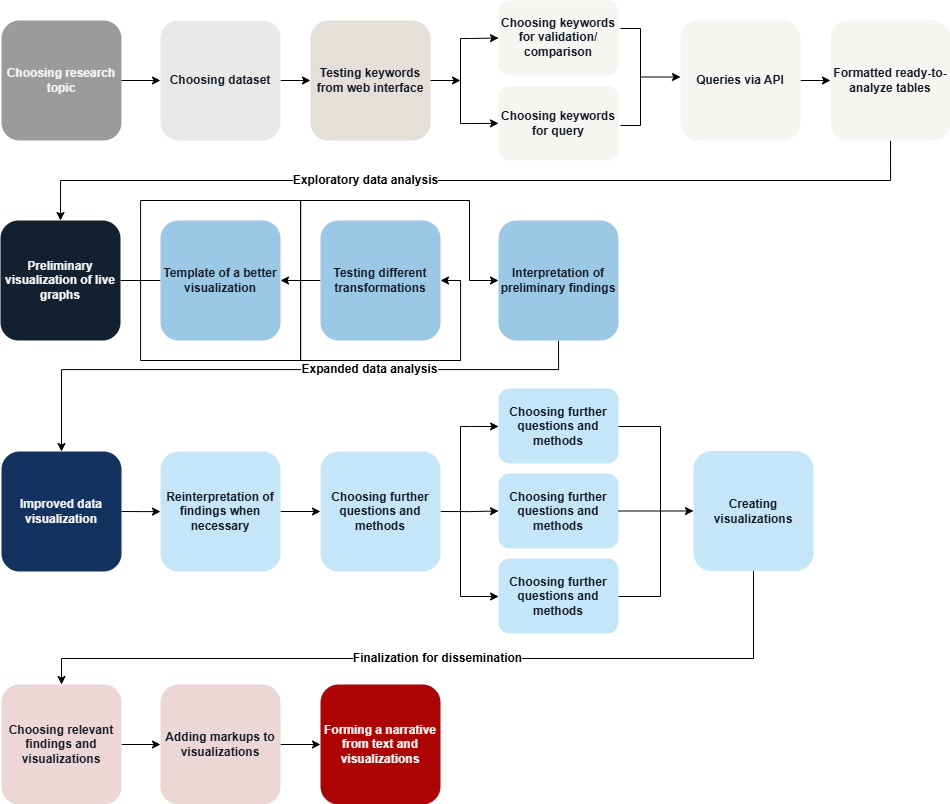
The workflow enables the analysis of mention frequencies across different categories over long time periods or with dense data, in order to reveal similarities and emerging patterns. Data is aggregated into matrices, which are used to createheatmapsthat allow large datasets to be presented visually in a clear and comparable manner. These visuals can be read both across time and across categories, enabling the comparison of different periods and topics, and combining intuitive qualitative visual analysis with quantitative methods. Mathematical transformations (e.g., normalization and logarithmic transformation) are applied to highlight relationships from different perspectives, especially when data values vary greatly. Additional perspectives are provided by other data science methods, such as time series vectorization and clustering.
In our example, we studied the mention frequency of the word “Ukraine” in 28 different languages over 15 years in the Twitter (now X) dataset, based on data obtained from the public API. The goal was to understand how and when attention directed at Ukraine in different languages increased or decreased.
- Authors:
- Mark Mets (Tallinn University, Estonian Literary Museum)
- Maximilian Schich (Tallinn University)
- Peter S. Dodds (University of Vermont, USA)
- Licence: CC-BY
- Date/version: 24.03.2026 v2
- Keywords (content): vector analysis, transformations, visualization, interdisciplinarity, Ukraine, social media, Twitter, attention, time series, n-gram
- Keywords (Tadirah): Data visualization, Sequence alignment, Distance measurement, Principal component analysis, Cluster analysis, Data mining
- Subject field: cultural studies
- Data media type: metadata, text
- Output: data visualization, scholarly article
- Related materials:
- Artikkel: Mets, M., Dodds, P. S., Schich, M. (2026). Crisis-induced differences in attention towards Ukraine in Twitter 2008-2023. arXiv preprint arXiv:2603.17899.
- Kood: https://github.com/markmets/Ukraine-Twitter
- Reference: Mets, Mark, Schich, Maximilian, Dodds, Peter S. (2026) Large-scale study of attention change trends using ngrams https://www.etkad.ee/humal/toovood/suurel-skaalal-ngrammidega/